Tom Oviste
Database for Multi-Channel Speech Enhancement: Mixing EARS and WHAM
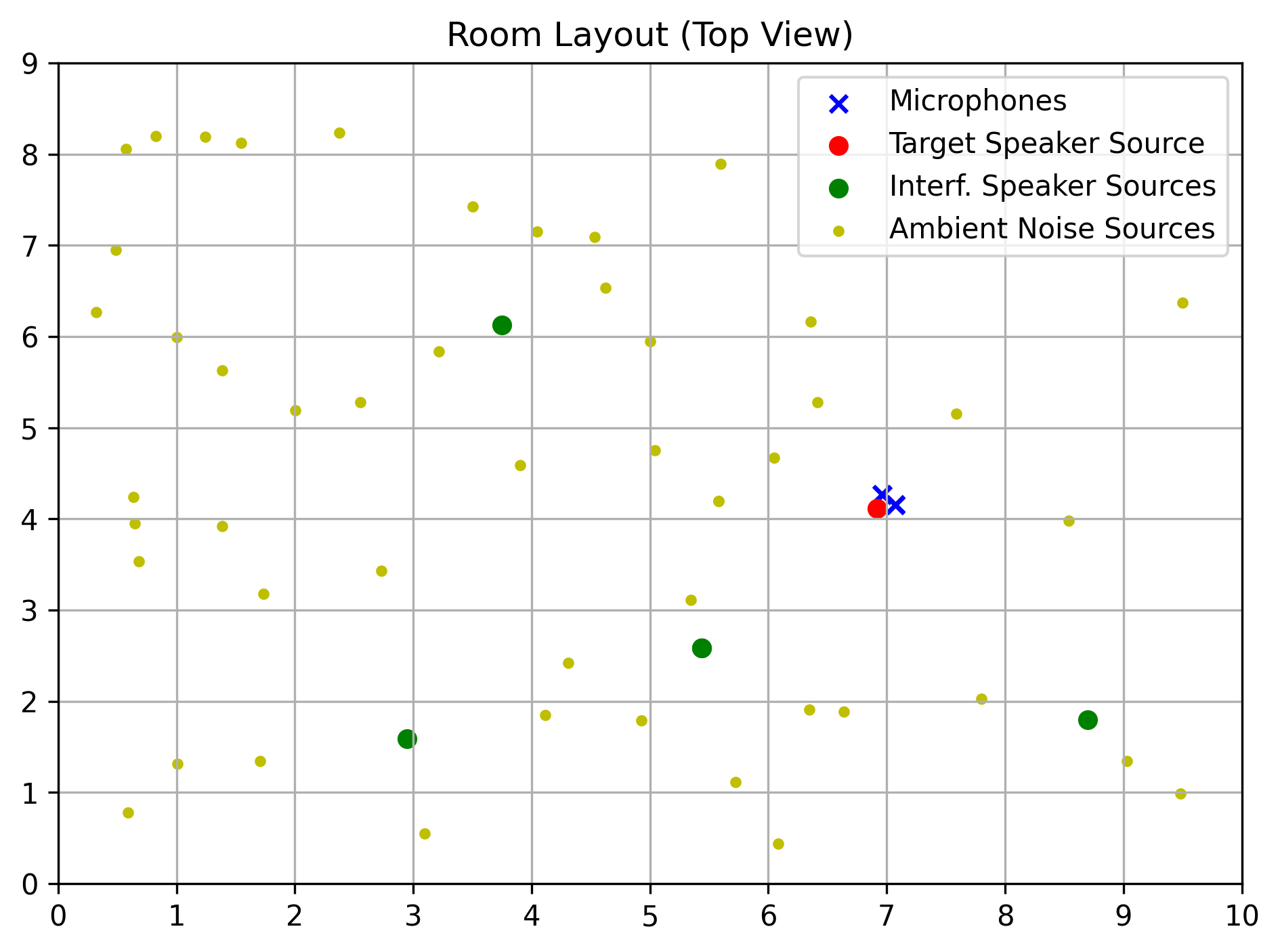
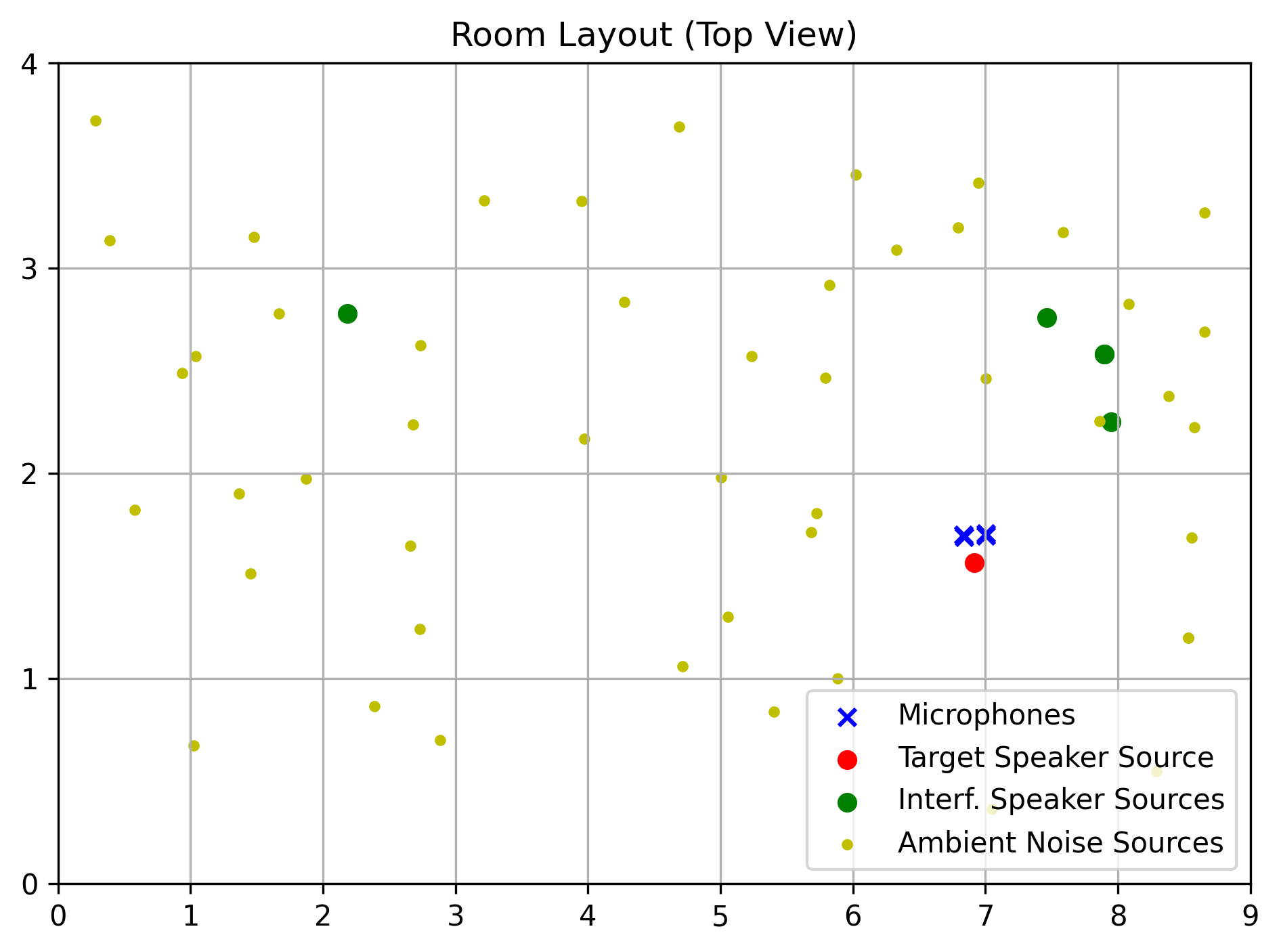
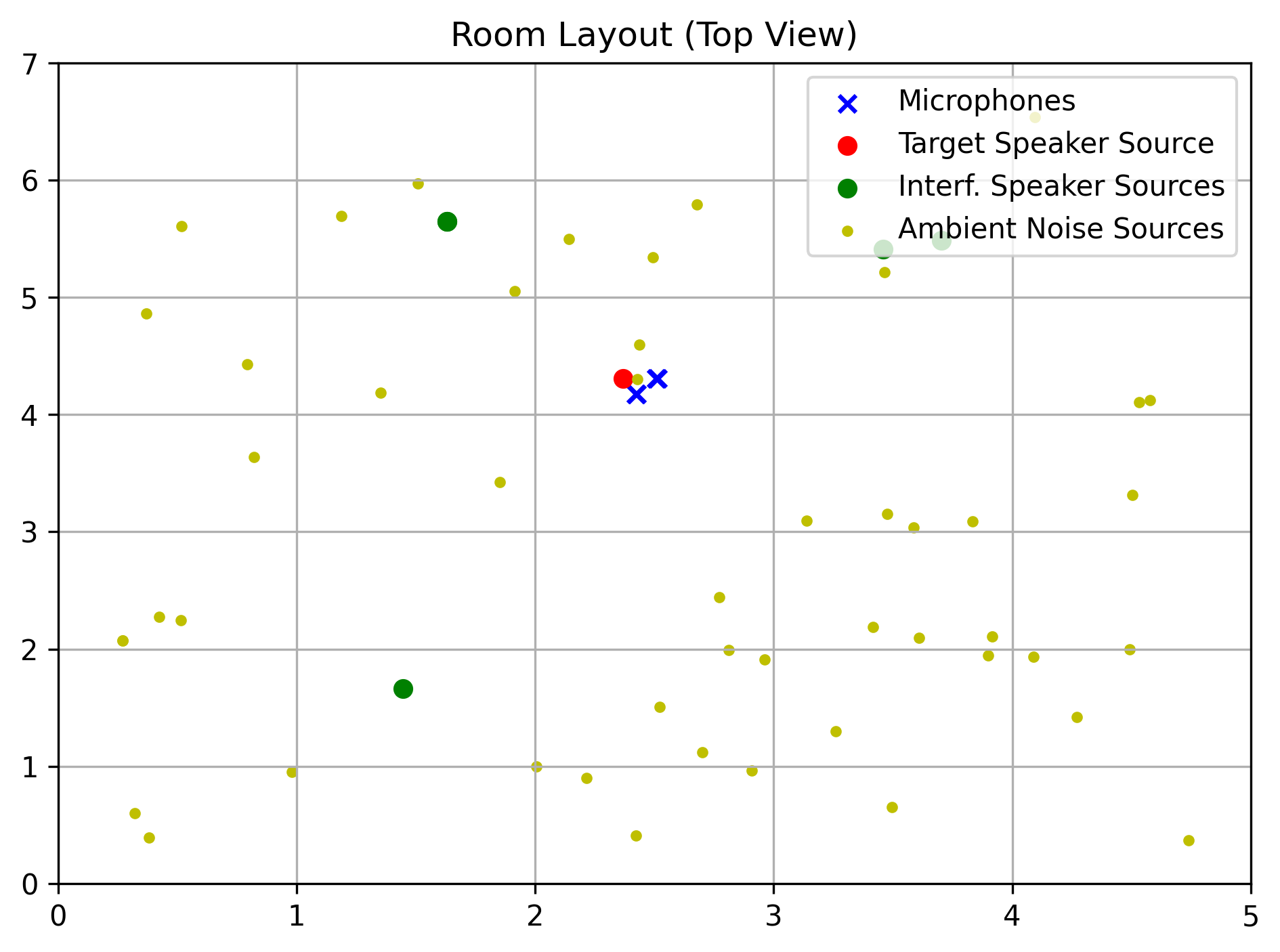
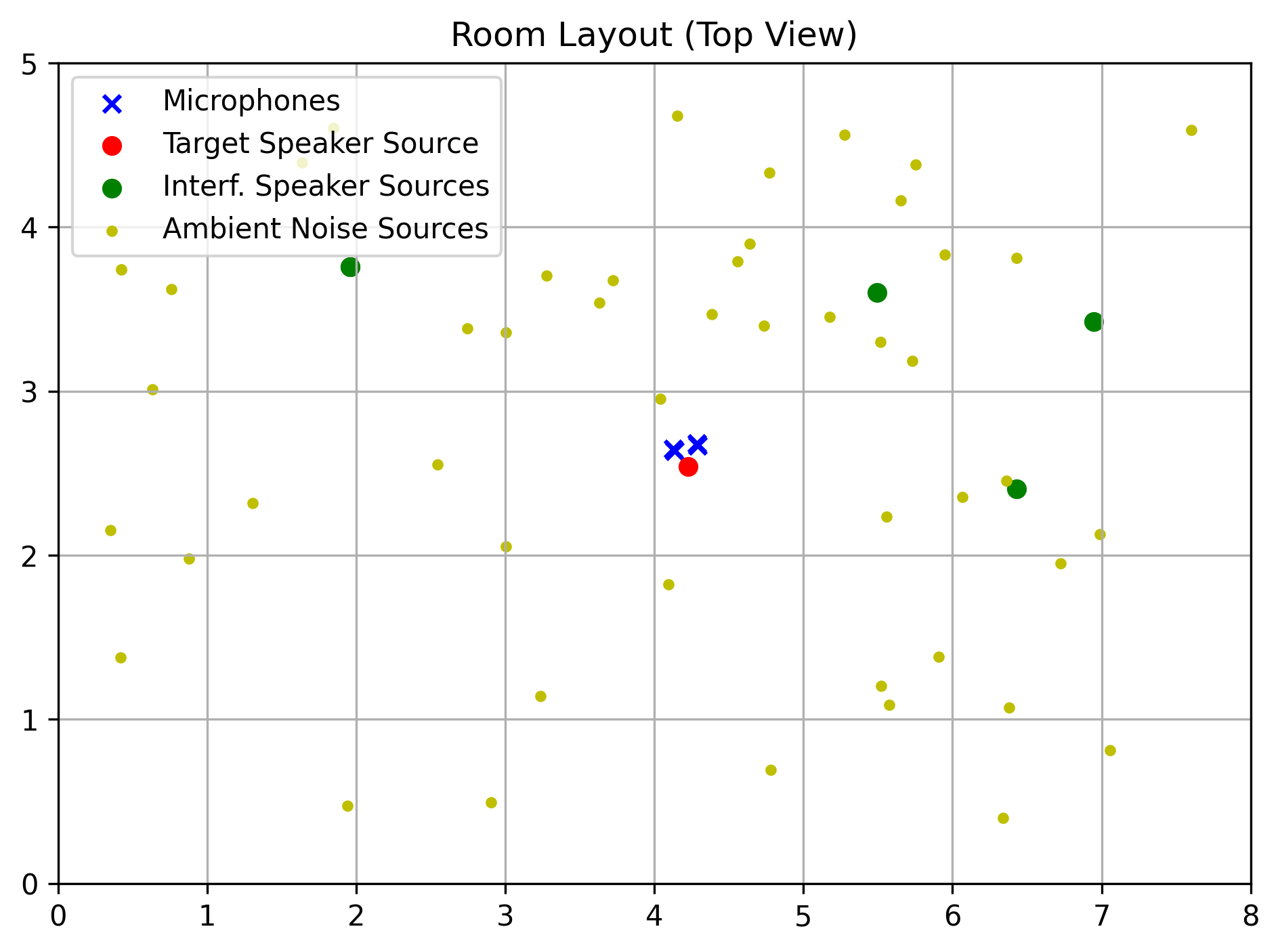
We present samples from MC-MIX-EARS-WHAM, the database we developed to train and evaluate multi-channel speech enhancement methods.
This database, comprised of approximately 40,000 pairs of clean-speech and noisy-mixture audio signals, was created using the Python programming language and the pyroomacoustics library.
We mixed clean-speech audio signals from the Expressive Anechoic Recordings of Speech (EARS) dataset, and ambient-noise audio signals from the WSJ0 Hipster Ambient Mixtures (WHAM!) dataset. Signals from EARS were filtered with a biquad highpass filter (cutoff frequency 70 Hz) to remove an observed high-power, low-frequency noise. More details on the pre-processing of EARS and on how the mixtures are generated will be avaible in future publication.
Our implementation of the data generation process can be found on GitHub. Here, we report signals with 2 channels for web compatibility – in practice, we use signals with 4 channels.
Disclaimer: this work focuses on multi-channel signals and is strictly independent from the single-channel “EARS-WHAM” dataset developed by the authors in the original EARS publication.
Sample 1: SIR = +6 dB, SNR = +6 dB
| Noisy Mixture | Clean Speech | Overall Noise |
|---|---|---|
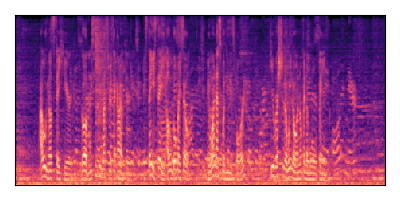 |
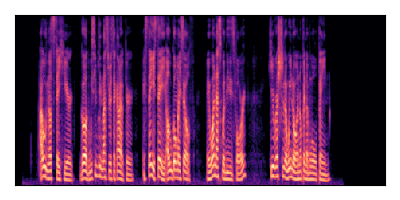 |
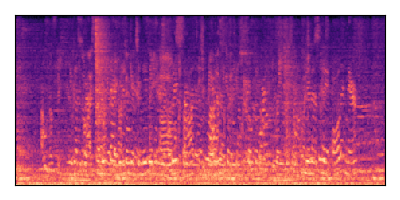 |
Sample 2: SIR = 0 dB, SNR = +6 dB
| Noisy Mixture | Clean Speech | Overall Noise |
|---|---|---|
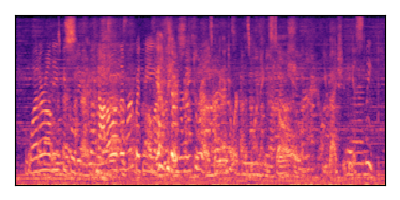 |
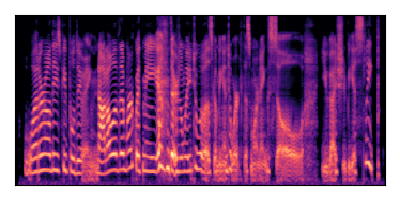 |
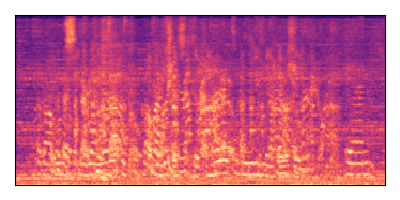 |
Sample 3: SIR = +6 dB, SNR = -6 dB
| Noisy Mixture | Clean Speech | Overall Noise |
|---|---|---|
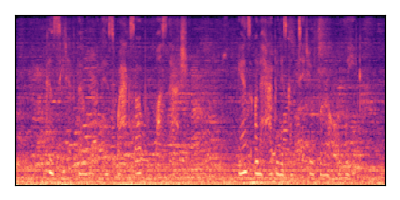 |
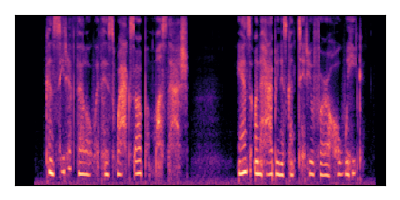 |
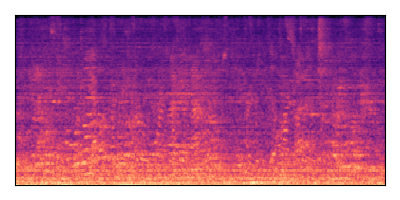 |
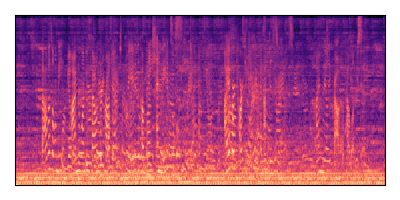
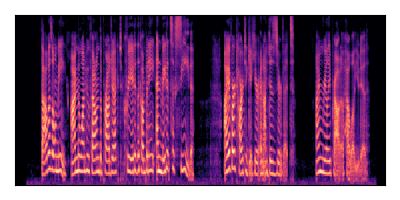
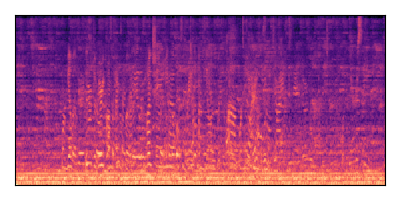
Sample 4: SIR = 0 dB, SNR = -6 dB
| Noisy Mixture | Clean Speech | Overall Noise |
|---|---|---|
 |
 |
 |